
Nagios [http://www.nagios.org/] je neoblíbenější OpenSource dohledový nástroj. Pomocí pluginů umožňuje monitorovat jakýmkoli protokolem libovolná zařízení a služby. Nejběžnější je sledování zařízení pomocí protokolu SNMP, případně sledování serverů použitím NRPE (Nagios Remote Plugin Executor). Nagios se nastavuje textovými konfiguračními soubory a ovládá pomocí webového rozhraní.
Nagios pracuje se 3 hlavními objekty (object):
- service – služby které chceme monitorovat (např. zatížení CPU, zda je v tiskárně dostatek toneru nebo zda nebyla překročena teplota ve sledované místnosti)
- host – samotná zařízení na kterých monitorujeme služby (např. server, tiskárna, teploměr atd.)
- contact – jsou osoby, kterým jsou zasílány zprávy o stavu služeb a zařízení (správci, technici atd.)
Tyto objekty je možné slučovat do skupin (group) pro přehlednější zobrazení souvisejících objektů ve webovém rozhraní a zjednodušení konfigurace.
Dále existují objekty timeperiods, které definují kdy jsou dohledována zařízení/služby a dále kdy jsou zasílány upozornění kontaktním osobám. Samotné pluginy jsou definovány pomocí objektů command. Ostatní objekty pro eskalaci problémů a nastavení závislostí zařízení jsou mimo rozsah tohoto článku (zájemci naleznou podrobnější informace v dokumentu Nagios Core Documentation, kapitola Object Configuration Overview, dostupném na adrese http://nagios.sourceforge.net/docs/nagios-3.pdf).
Instalace Nagiosu
Tento článek je určen pro uživatele se základními znalostmi operačního systému GNU/Linux, proto zde není uveden postup instalace Nagiosu ze zdrojového kódu (pro zájemce o instalaci ze zdrojového kódu je balík dostupný na http://www.nagios.org/download/core/, instalace se provádí klasicky ./configure, make all, make install).
Začátečníkům doporučuji distribuci Ubuntu [http://www.ubuntu.com/]. Příklady v tomto článku vychází ze standardně nainstalovaného Ubuntu Server Edition 9.10 [http://www.ubuntu.com/getubuntu/download-server].
Instalaci Nagiosu provedeme příkazem:
helpdesk@monitoring:~$ sudo aptitude install nagios3
Instalátor automaticky vybere potřebné balíky pro správnou funkci Nagiosu (webserver Apache, SNMP knihovny, mailserver atd.), instalaci těchto balíků potvrďte. Po instalaci budete pravděpodobně vyzváni k nastavení Postfixu (mailserver), zvolte možnost Internet Site, a zadejte název a doménu serveru (FQDN, např. monitoring.company.com). Dále zadejte heslo pro webový přístup do Nagiosu.
Po instalaci můžete ověřit dostupnost Nagiosu pomocí webového prohlížeče na adrese http://192.168.1.1/nagios3/ kde 192.168.1.1 je IP adresa serveru na který jste nainstalovali Nagios. Jméno pro přihlášení je nagiosadmin a heslo jste zadali při instalaci Nagiosu. Pokud jste heslo zapomněli, zadejte příkaz sudo htpasswd /etc/nagios3/htpasswd.users nagiosadmin a zadejte nové heslo.
Tip: Pro zjištění IP adresy serveru zadejte příkaz sudo ifconfig:
eth0 Link encap:Ethernet HWaddr 08:00:27:3d:d9:f1 inet addr:192.168.1.1 Bcast:192.168.1.255 Mask:255.255.255.0 inet6 addr: fe80::a00:27ff:fe3d:d9f1/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:4300 errors:0 dropped:0 overruns:0 frame:0 TX packets:2946 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:444119 (444.1 KB) TX bytes:1304450 (1.3 MB) Interrupt:11 Base address:0xc020
Pokud jste instalovali server s nastavením IP adresy pomocí DHCP a nyní si přejete zadat IP adresu ručně, upravte soubor /etc/network/interfaces
auto eth0 iface eth0 inet static address 192.168.1.1 netmask 255.255.255.0 gateway 192.168.1.254
Chcete-li naopak nastavit automatickou konfiguraci z DHCP, upravte soubor následovně:
auto eth0 iface eth0 inet dhcp
Pro aktivaci změn nastavení sítě musíte spustit příkaz /etc/init.d/networking restart.
Pro snadnější orientaci doporučuji nainstalovat Midnight Commander:
helpdesk@monitofanring:~$ sudo aptitude install mc
Midnight Commander se spouští příkazem mc. V distribuci Ubuntu není standardně nastavený vnitřní editor, pro jeho aktivaci stiskněte F9 → Options → Configuration... → vyberte use internal edIt → Save. Soubory se editují pomocí klávesy F4. Klávesa ESC funguje jako příkazový prefix, pro ukončení editace musíte klávesu ESC stisknout 2x (toto chování je z důvodu podpory „hloupých“ terminálů, nepodporuje-li terminál např. funkční klávesy, je možné stisknutí klávesy F4 nahradit postupným stisknutím kláves ESC a 4). Nový soubor založíme pomocí SHIFT+F4. Pokud vkládáte soubor ze schránky a nechcete, aby MC automaticky odsazoval bloky, stiskněte F9 → Options → General... → zrušte Return does autoindent → OK.
Pro vzdálený přístup na terminál serveru nainstalujte SSH:
helpdesk@monitoring:~$ sudo aptitude install openssh-server
Mějte na paměti, že instalací SSH serveru umožňujete vzdálený přístup k serveru, a proto by mělo být nastaveno dostatečně silné heslo. Pro přístup k serveru z MS Windows doporučuji program PuTTY [http://www.chiark.greenend.org.uk/~sgtatham/putty/].
Tip: V unixových systémech může operace jako instalace systémových programů, jejich spouštění, změny nastavení atd. provádět pouze superuživatel (uživatelský účet root). Aby nebylo nutné během instalace a nastavení Nagiosu před každým příkazem zadávat sudo, můžete přepnout na superuživatele příkazem sudo su -.
helpdesk@monitoring:~$ whoami helpdesk (jsme přihlášeni jako uživatel helpdesk) helpdesk@monitoring:~$ sudo su - [sudo] password for helpdesk: zadejte heslo aktuálně přihlášeného uživatele root@monitoring:~# whoami root (jsme přihlášeni jako uživatel root, resp. příkazy budou prováděny s oprávněním uživatele root) root@monitoring:~# exit logout helpdesk@monitoring:~$
Všimněte si, že prompt superuživatele končí znakem #, zatímco prompt běžného uživatele končí znakem $.
Nastavení Nagiosu
Konfigurační soubory Nagiosu jsou umístěny v adresáři /etc/nagios3. Infrastrukturu, která se bude monitorovat, definujeme pomocí souborů v adresáři /etc/nagios3/conf.d. Pro pochopení nastavení Nagiosu provedeme zálohu předinstalovaného nastavení infrastruktury a vytvoříme vlastní konfiguraci.
helpdesk@monitoring:~$ sudo su - [sudo] password for helpdesk: root@monitoring:~# mkdir /root/nagios_backup root@monitoring:~# mv /etc/nagios3/conf.d/* /root/nagios_backup
Časové úseky – timeperiod
Časové úseky, kdy je prováděn monitoring a jsou upozorňovány kontaktní osoby, nastavíme v souboru /etc/nagios3/conf.d/timeperiods.cfg. Každý objekt je definován pomocí define timeperiod { … }. Parametr timeperiod_name říká jak se na daný časový úsek budeme odkazovat v konfiguraci služeb, zařízení a kontaktů. Parametr alias říká, jak se bude časový úsek zobrazovat. Dále následuje výčet časů po které je daný časový úsek platný. V každém dnu je možné nastavit více časových úseků (např. pondělí mimo pracovní dobu: monday 00:00-8:00,18:00-24:00).
define timeperiod { timeperiod_name 24x7 alias Nonstop 24x7 monday 00:00-24:00 tuesday 00:00-24:00 wednesday 00:00-24:00 thursday 00:00-24:00 friday 00:00-24:00 sunday 00:00-24:00 saturday 00:00-24:00 }
define timeperiod { timeperiod_name 10x5 alias Work hours 10x5 monday 08:00-18:00 tuesday 08:00-18:00 wednesday 08:00-18:00 thursday 08:00-18:00 friday 08:00-18:00 }
define timeperiod { timeperiod_name never alias Never }
Tento příklad definuje tři časové úseky. První 24x7 je pro non-stop dohled. Druhý časový úsek 10x5 je platný v pracovní dny od 8:00 do 18:00. Třetí časový úsek never není nikdy platný (ten použijeme v případě, že nechceme zasílat žádná upozornění).
Kontaktní osoby – contact
Osoby, kterým jsou zasílána upozornění, se nastavují v souboru /etc/nagios3/conf.d/contacts.cfg. Parametry host_ a service_ notification_period nastavíme kdy bude kontakt dostávat upozornění. Parametr host_notification_options říká, jaké druhy zpráv se mají zasílat kontaktu:
Parametr service_notification_options říká, jaké druhy zpráv se mají zasílat kontaktu:
Parametry host_ a service_ notification_commands říkají, jaký příkaz bude spuštěn pro zaslání informace o události na zařízení resp. službě. Parametry email a address1 jsou předávány jako argumenty příkazům.
define contact { contact_name helpdesk alias Company Helpdesk host_notification_period 24x7 service_notification_period 24x7 host_notification_options d,u,r service_notification_options u,w,c,r service_notification_commands notify-service-by-email host_notification_commands notify-host-by-email email helpdesk@company.com }
define contact { contact_name technician1_mail alias John Doe host_notification_period 10x5 service_notification_period 10x5 host_notification_options n service_notification_options w,c,r service_notification_commands notify-service-by-email host_notification_commands notify-host-by-email email john.doe@company.com }
Takto jsme definovali 3 kontakty. První helpdesk bude nepřetržitě zasílat události o změně stavu zařízení a služeb na e-mail helpdesk@company.com. Druhý kontakt technician1_mail bude během pracovní doby (viz. timeperiod 10x5) zasílat technikovi události o změně stavu služeb na e-mail john.doe@company.com.
Kontaktní skupiny – contactgroup
Abychom nemuseli v definici každého zařízení a služby uvádět výčet kontaktních osob, můžeme definovat skupiny kontaktů v souboru /etc/nagios3/conf.d/contactgroups.cfg.
define contactgroup { contactgroup_name support alias Company Support members helpdesk, technician1_mail }
Zařízení a služby, které budou mít nastavenou kontaktní skupinu support, budeme zasílat na kontakty helpdesk a technician1_mail.
Zařízení – host
Chceme-li monitorovat nějakou službu nebo veličinu, musíme definovat, na jakém zařízení je dostupná. Zjednodušeně řečeno, host odpovídá IP adrese zařízení. Před tím, než začneme do Nagiosu přidávat konkrétní zařízení, připravíme šablonu, podle které budou nastaveny parametry monitoringu, abychom je nemuseli opakovaně definovat na každém zařízení. Parametr name říká, jak se na daný host (v tomto případě šablonu) budeme odkazovat dále v konfiguraci. Jak často chceme být informováni v případě, že je zařízení stále nedostupné, definujeme parametrem notification_interval. Parametry notification_period a check_period říkají, v jakých časových úsecích se budou zasílat notifikace resp. provádět kontroly dostupnosti. Dále definujeme kontrolu stavu zařízení normal_check_interval, není-li zařízení dostupné, budeme kontrolovat dostupnost retry_check_interval a to tolikrát, kolik udává hodnota max_check_attempts. Způsob ověření dostupnosti zařízení se definuje parameterm check_command. Parametrem contact_groups říkáme, jaká skupina kontaktů bude upozorněna. To, že se jedná o šablonu, určuje parametr register 0. Šablonu uložíme do souboru /etc/nagios3/conf.d/tmplates.cfg.
define host { name standard-host notifications_enabled 1 notification_interval 0 notification_period 24x7 notification_options d,u,r check_period 24x7 normal_check_interval 5 retry_check_interval 1 max_check_attempts 10 first_notification_delay 10 check_command check-host-alive contact_groups support register 0 }
Tímto jsme definovali šablonu standard-host. Upozornění o tom, že je zařízení nedostupné, obdržíme pouze jednou. Upozornění i samotné kontroly budou prováděny non-stop. Dostupnost zařízení se bude kontrolovat každých 5 minut. Nebude-li zařízení dostupné, bude se zkoušet každou minutu po dobu 10 minut jeho dostupnost, poté se opět bude kontrolovat každých 5 minut. Pokud se zařízení stane opět dostupné do 10 minut od výpadku (parametr first_notification_delay), nebude zasláno upozornění o nedostupnosti. Zařízení bude kontrolováno příkazem check-host-alive, tj. pomocí protokolu ICMP (ping). Upozornění budou předávána skupině support.
Nyní můžeme definovat zařízení, která chceme monitorovat. Pro začátek nastavíme samotný server Nagios. Parametrem use definujeme, z jaké šablony se použijí parametry zařízení. Dále nastavíme, jak se budeme odkazovat na zařízení v konfiguraci parametrem host_name. IP adresa, prostřednictvím které je zařízení dostupné, je definována parametrem address. Ikonka zařízení se definuje parametrem icon_image (ikony jsou uloženy v adresáři /usr/share/nagios/htdocs/images/logos/). Konfiguraci uložíme do souboru /etc/nagios3/conf.d/localhost.cfg
define host { use standard-host host_name localhost alias Nagios server address 127.0.0.1 icon_image base/linux40.png }
Server Nagios použije parametry šablony standard-host. Služby, běžící na tomto serveru, se budou odkazovat na jméno localhost. Server je dostupný prostřednictvím loopbacku (IP adresa 127.0.0.1). Jako ikonka bude zobrazeno logo Linuxu.
Služby – service
Nyní se dostáváme k definicím jednotlivých služeb či veličin, které budeme na zařízení monitorovat. Služby mají obdobné parametry jako zařízení (host). Proto nejdříve nastavíme šablonu, abychom nemuseli u každé služby znovu definovat obecné parametry. Šablonu služby přidáme do souboru /etc/nagios3/conf.d/tmplates.cfg.
define service { name standard-service notifications_enabled 1 notification_interval 0 notification_period 24x7 notification_options u,w,c,r check_period 24x7 normal_check_interval 5 retry_check_interval 1 max_check_attempts 4 first_notification_delay 5 contact_groups support register 0
Šablona služby se liší od šablony zařízení jen kratší dobou, po kterou je služba testována v případě nekorektního stavu. Nezapomeňte opět přidat parametr register 0, aby nebyla šablona zaregistrována jako normální služba.
Nyní můžeme přidat služby, které chceme na serveru monitorovat. Opět nejdříve nastavíme parametrem use z jaké šablony má služba převzít standardní parametry. Každá služba je svázána se zařízením (host) parametrem host_name. Klíčovým parametrem je check_command, kterým definujeme, jakým pluginem a s jakými parametry má být služba monitorována. Jednotlivé parametry jsou odděleny znakem vykřičník „!“. Do souboru /etc/nagios3/conf.d/localhost.cfg přidáme následující dvě služby:
define service { use standard-service host_name localhost service_description Disk free check_command check_all_disks!10%!5% }
define service { use standard-service host_name localhost service_description System load check_command check_load!5.0!4.0!3.0!10.0!6.0!4.0 }
Tímto jsme definovali dohled volného místa na disku Disk free a dohled zatížení serveru System Load. Volné místo na disku sledujeme příkazem check_all_disks, kterému jsme předali dva argumenty. Po obsazení 90 % diskové kapacity (10 % volného místa) bude vyvolána událost warning a po obsazení 95 % diskové kapacity bude vyvolána událost critical. Události obdrží členové kontaktní skupiny support (načtěno pomocí parametru use ze šablony standard-service).
Aktivace změn nastavení v Nagiosu
Nagios načítá soubory s konfigurací při spuštění. Pro aktivaci změn je potřeba provést reload Nagiosu příkazem:
root@monitoring:~# /etc/init.d/nagios3 reload
Pokud je v konfiguračních souborech chyba, budete upozorněni:
Reading configuration data...
Error: Invalid host object directive 'registe'. Error: Could not add object property in file '/etc/nagios3/conf.d/templates.cfg' on line 14.
***> One or more problems was encountered while processing the config /files...
V tomto případě jsme omylem zadali v souboru /etc/nagios3/conf.d/templates.cfg na řádce 14 parametr „registe“ místo správného „register“. Po opravení chyby znovu proveďte reload Nagiosu, je-li konfigurace již v pořádku, bude zobrazena následující hláška:
* Reloading nagios3 monitoring daemon configuration /files nagios3 [ OK ]
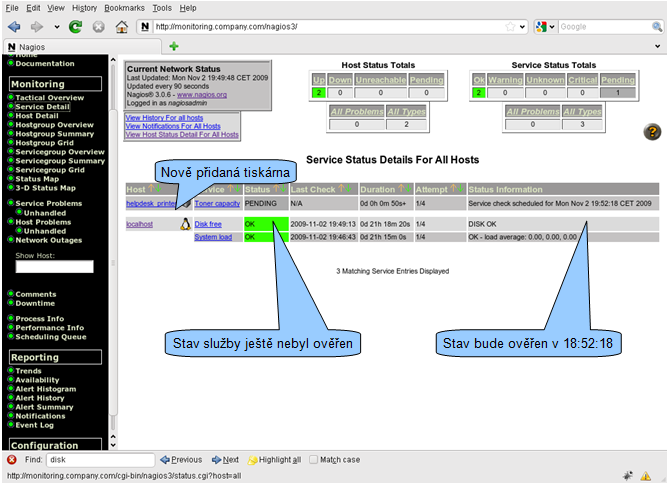
Webové rozhraní Nagios
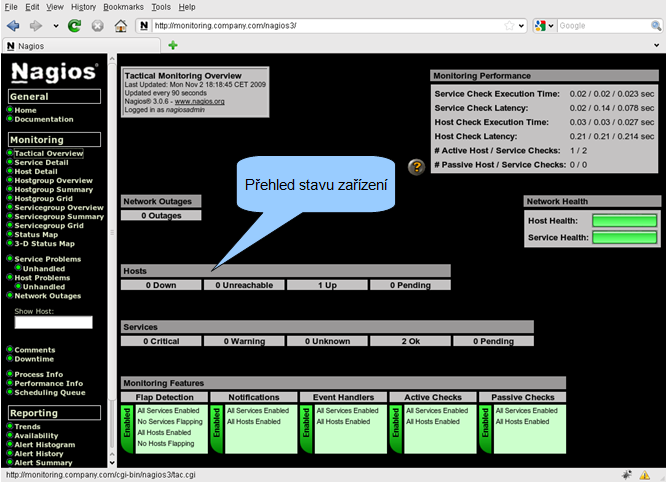
Hlavní stránkou monitoringu je Tactical Overview.
Kliknutím na počet zařízení nebo služeb v určitém stavu se zobrazí stránka se zařízeními resp. službami ve zvoleném stavu.
Přehled monitorovaných zařízení získáme kliknutím na položku Host Detail. Stav každého zařízení je pro rychlou orientaci indikován barevně. Kliknutím na název zařízení získáte detailní informace o zařízení, včetně možnosti pozastavit sledování zařízení, nastavit plánovaný výpadek zařízení atd. Přehled služeb na zařízení získáte kliknutím na ikonku semaforu.

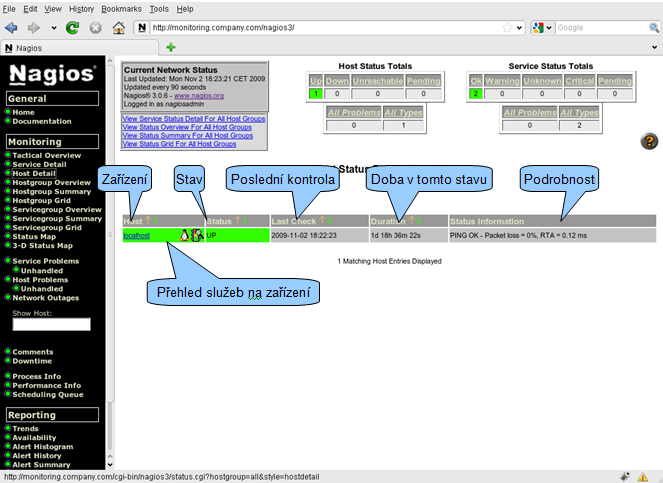
Podle vzorové konfigurace Nagios monitoruje jedno zařízení. Poslední kontrola proběhla 2.11.2009 v 18:22:23. Zařízení je již 1 den a 18 hodin ve stavu UP. Výsledek testu je OK, ztrátovost 0 %, odezva 120 μs.
Přehled služeb je obdobný jako přehled zařízení. Dostupný je pod položkou Service Detail. Služby jsou seskupeny podle zařízení na kterých jsou provozovány.
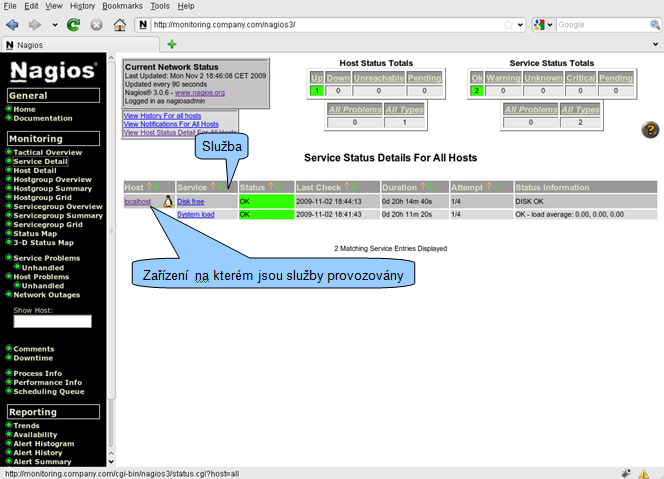
Sledování vlastní SNMP služby
Přehled pluginů (command), kterými je Nagios schopen monitorovat služby, je dostupný pomocí webového rozhraní pod položkou View Config nebo přímo v souborech v adresáři /etc/nagios-plugins/config/. Není-li plugin k dispozici, musíme vytvořit nový command, kterým danou službu budeme sledovat. Definice pluginu obsahuje název command_name, kterým se budeme na plugin odkazovat. Dále se specifikuje, jaký příkaz command_line se pro zjištění stavu služby má spustit.
Kapacita zásobníku toneru
Například pro sledování kapacity zásobníku toneru v tiskárně můžeme využít protokolu SNMP. OID obsahující množství toneru je .1.3.6.1.2.1.43.11.1.1.9.1.1. Aby nebylo nutné pro každou tiskárnu definovat vlastní plugin, IP adresu, SNMP komunitu a hodnoty pro warning a critical předáme z konfigurace jednotlivých služeb pomocí proměnných. Vytvoříme soubor /etc/nagios3/conf.d/commands.cfg.
define command {
command_name printer_toner
command_line /usr/lib/nagios/plugins/check_snmp -H '$HOSTADDRESS$' -C '$ARG1$' -o .1.3.6.1.2.1.43.11.1.1.9.1.1 -w '$ARG2$': -c '$ARG3$': -l 'Toner capacity' -u '%'
}
Plugin pro sledování kapacity zásobníku toneru jsme pojmenovali printer_toner. Součástí standardních pluginů Nagiosu je program pro získávání hodnot pomocí protokolu SNMP. Při aktivaci pluginu pro zjištění aktuálního stavu bude nahrazena proměnná $HOSTADDRESS$ za konkrétní adresu (parametr address), uvedenou v definici zařízení (host) tiskárny. Další proměnné $ARG#$ jsou doplněny podle nastavení parametru check_command v definici konkrétní služby (service).
Tiskárnu a sledování kapacity zásobníku toneru nastavíme v souboru /etc/nagios3/conf.d/helpdesk_printer.cfg.
define host {
use standard-host
host_name helpdesk_printer
alias Helpdesk printer
address 192.168.12.200
icon_image base/hp-printer40.png
}
define service { use standard-service service_description Toner capacity host helpdesk_printer check_command printer_toner!public!10%!5% }
Plugin, který bude použit, jsme nastavili první částí parametru check_command v definici služby. Proměnná $HOSTADDRESS$ bude obsahovat hodnotu 192.168.12.200 podle parametru address v definici zařízení. Proměnné $ARG#$ budou obsahovat jednotlivé hodnoty, oddělené znakem „!“ v parametru check_command (tedy $ARG1$ = public, $ARG2$ = 10%, $ARG3$ = 5%). Nagios tak při kontrole této konkrétní služby provede příkaz:
/usr/lib/nagios/plugins/check_snmp -H '192.168.12.200' -C 'public' -o .1.3.6.1.2.1.43.11.1.1.9.1.1 -w '10%': -c '5%': -l 'Toner capacity' -u '%'
Tento příkaz můžete spustit v terminálu pro ověření správného nastavení.
Nezapomeňte aktualizovat konfiguraci ve spuštěném Nagiosu pomocí příkazu /etc/init.d/nagios3 reload.
Sledování veličin
Sledování veličin je obdobné jako sledování služeb zařízení. V tomto příkladu přidáme zařízení, která mají podporu pro sledování veličin Nagiosem. Ze stránek HW group stáhneme plugin (command) pro sledování zařízení Poseidon (nebo HWg-STE / Damocles).
Stačí rozbalit stažené soubory a podle návodu umístit .pl soubory do /opt/hwg/, adresář s obrázky do /usr/share/nagios3/htdocs/images/logos/ a soubor hwg.cfg do /etc/nagios-plugins/config/.
Zjistíme ID senzorů veličin, které chceme sledovat.
Poseidon
Pro Poseidon z adresy http://poseidon.hwg.cz/values.xml:
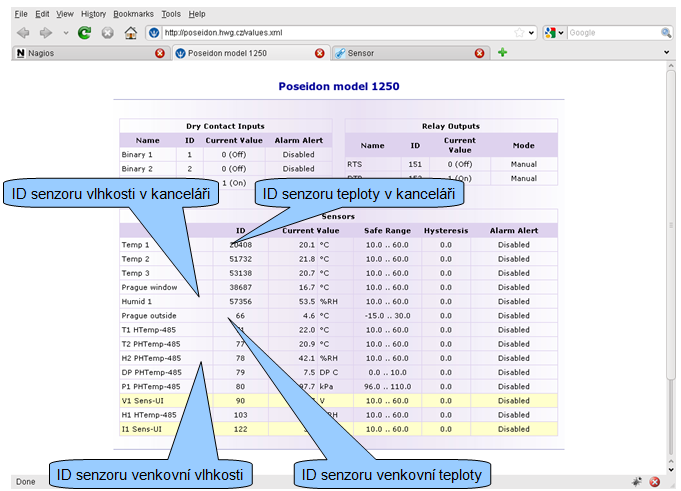
Na základě těchto údajů vytvoříme konfigurační soubor /etc/nagios3/conf.d/poseidon_demo.cfg.
define host {
use standard-host
host_name poseidon.hwg.cz
alias Poseidon demo
address poseidon.hwg.cz
icon_image hwg/poseidon40.png
}
define service { use standard-service service_description Office temp. host poseidon.hwg.cz check_command check_hwg_poseidon!public!20408 }
define service { use standard-service service_description Office humidity host poseidon.hwg.cz check_command check_hwg_poseidon!public!57356 }
define service { use standard-service service_description Prague temp. host poseidon.hwg.cz check_command check_hwg_poseidon!public!66 }
define service { use standard-service service_description Prague humidity host poseidon.hwg.cz check_command check_hwg_poseidon!public!78 }
Všimněte si, že v konfiguraci nenastavujeme hodnoty warning a critical, ty jsou automaticky získány ze zařízení. Důležité parametry, které musíme nastavit, jsou jen address zařízení a ID senzorů v parametrech check_command služeb (veličin).
STE
Obdobným způsobem zjistíme ID senzorů zařízení STE z adresy http://ste.hwg.cz/:
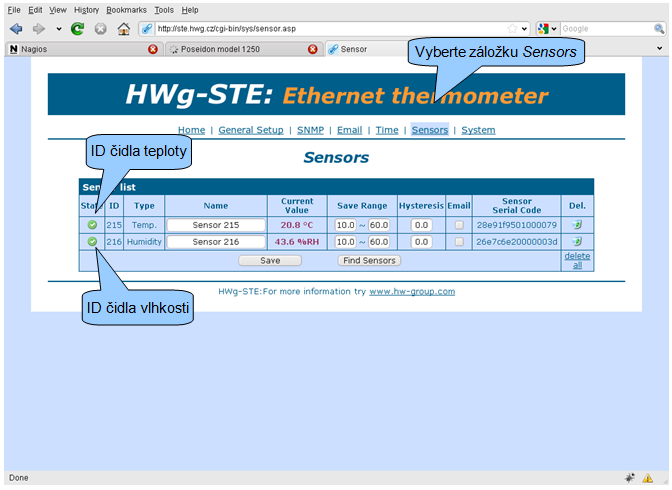
Na základě těchto údajů vytvoříme konfigurační soubor /etc/nagios3/conf.d/ste_demo.cfg.
define host {
use standard-host
host_name ste.hwg.cz
alias STE demo
address ste.hwg.cz
icon_image hwg/ste40.png
}
define service { use standard-service service_description Office temp. host ste.hwg.cz check_command check_hwg_ste!public!215 }
define service { use standard-service service_description Office humidity host ste.hwg.cz check_command check_hwg_ste!public!216 }
Nezapomeňte aktualizovat konfiguraci ve spuštěném Nagiosu pomocí příkazu /etc/init.d/nagios3 reload.



