
![]() Rodina mikrokontrolérů (MCU) RX představuje výsledek desetiletých zkušeností, seriózního zkoumání podstatných vlivů a také bedlivého naslouchání „hlasu zákazníka“. Obvody RX se přitom zaměřují na samotné jádro polovodičového prostoru se strukturami R8C, umístěnými níže a prvky SH výše. V případě RX hovoříme o poctivém, 32bitovém přístupu, založeném na vylepšené architektuře Harvard CISC, dosahující mimořádně vysoké hustoty kódu, stejně jako ve své třídě nejlepších výkonů 1.65 MIPSů / MHz. Všechny prvky RX jsou v Renesas vyráběny za přispění nadmíru spolehlivých a rovněž časem prověřených, 90 nm embedded Flash procesů, podporujících nulovou prodlevu při provádění kódu a to až do 100 MHz.
Rodina mikrokontrolérů (MCU) RX představuje výsledek desetiletých zkušeností, seriózního zkoumání podstatných vlivů a také bedlivého naslouchání „hlasu zákazníka“. Obvody RX se přitom zaměřují na samotné jádro polovodičového prostoru se strukturami R8C, umístěnými níže a prvky SH výše. V případě RX hovoříme o poctivém, 32bitovém přístupu, založeném na vylepšené architektuře Harvard CISC, dosahující mimořádně vysoké hustoty kódu, stejně jako ve své třídě nejlepších výkonů 1.65 MIPSů / MHz. Všechny prvky RX jsou v Renesas vyráběny za přispění nadmíru spolehlivých a rovněž časem prověřených, 90 nm embedded Flash procesů, podporujících nulovou prodlevu při provádění kódu a to až do 100 MHz.
Rodina obvodů RX se bude na pozici platformově založeného konceptu, umožňujícího vývoj nových produktů, během pouhých šesti měsíců velmi svižně rozrůstat. Ucelená nabídka, kterou jsme již zmiňovali (Connectivity Stream), pak bude ještě během roku 2010 zahrnovat více než 30 produktových verzí, přičemž v rámci univerzálního nasazení hovoříme téměř o 40. V rámci této rodiny rovněž zmiňujeme silný, vycházející potenciál v podobě ASSP (Application-Specific-Standard-Products), představující jasné výhody pro zákazníky vertikálních trhů, protože ASSP, budou – li použity v aplikacích pro které byly zamýšleny, pokaždé předčí univerzální MCU. Jako první příklad uvádíme 15 produktů, určených pro motory a jejich řízení. Za zmínku rovněž stojí RX a jejich návrh, podporující jednoduchý přechod, při kterém jsme měli na mysli desítky tisíc zákazníků, využívajících H8 a M16C. Byla opětovně nasazena celá řada hodnotných a také osvědčených periférií. Soubor nástrojů zase pracuje pod HEW IDE, který je v souvislosti s námi vyráběnými obvody dobře znám. Jednoduše řečeno, obvody RX jsme v Renesas vyvinuli proto, abychom mohli našim zákazníkům nabídnout nejlepší možnou technologii MCU, která bude prostě a jednoduše lepší než kterákoli jiná architektura MCU střední třídy.
Vylepšená architektura Harvard CISC
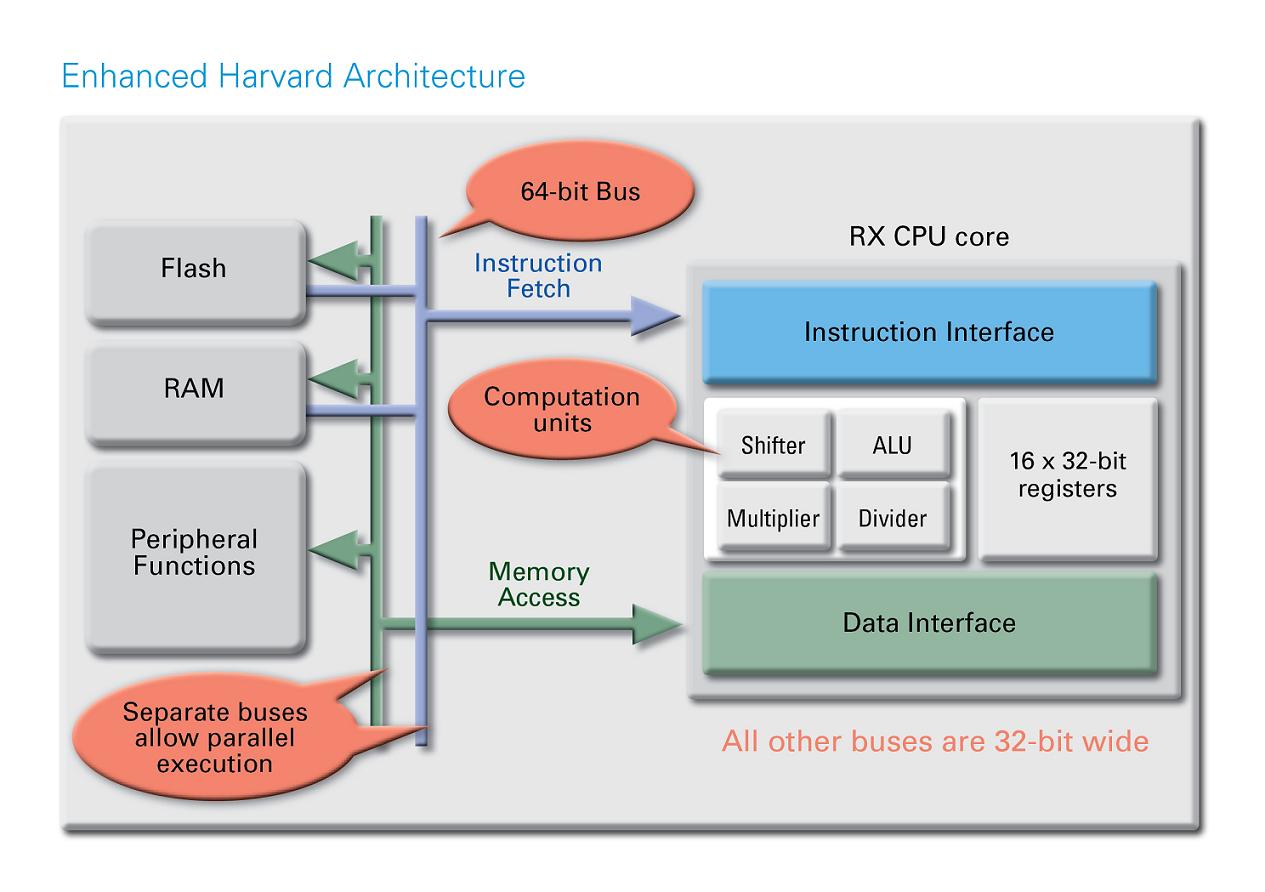
Jak již bylo uvedeno, RX vychází z rozšířené Harvardské architektury, která má oddělené paměti a také sběrnice pro instrukce a data, takže můžeme souběžně přistupovat k datům i vyvolávání instrukcí. Nevýhodou klasické Harvardské architektury je skutečnost, že pevná data budou uložena v kódovém prostoru s potřebou přesunu do datové oblasti (obvykle RAM) po resetu. Takový postup ale prodlužuje čas, potřebný k nabootování a také zbytečně “plýtvá” drahocennou pamětí RAM. V případě klasické Von – Neumannovy architektury zase máme k dispozici jen jednu paměť / sběrnici pro kód a data, čímž se takovému nedostatku můžeme vyhnout, ovšem za cenu pomalejšího přístupu. S vylepšeními v podobě struktur RX však dostáváme do ruky to nejlepší z obou světů: RX používají samostatné sběrnice (pro kód dokonce 64 bitů) spolu s unifikovanou pamětí a proto jsou tak rychlé jako v případě Harvardu a ještě k tomu šetří RAM, podobně jako Von – Neumann.
Výzkum zkoumal vliv počtu registrů na rychlost, vlastnosti kódu a také velikost samotného čipu, přičemž k nalezení nejlepšího počtu univerzálních registrů byl nasazen zákaznický kód. Studie prokázala, že v případě osmi registrů výrazně utrpí výkon a velikost kódu bude ještě k tomu zbytečně velká. S rostoucím počtem registrů se pak velikost kódu zmenšuje a výkonnost narůstá. Zároveň však také zvyšujeme rozměry daného čipu včetně jeho složitosti. Instrukce ADD má například délku dva byte a může kódovat 16 registrů. Kdyby se počet registrů zvýšil na více než 16, mohl by se formát instrukce rozrůst o další byte, aby se tak přizpůsobil dodatečným registrům. Zároveň by také ale došlo k navýšení rozměrů použitého čipu, odrážejícímu vzrůstající délku instrukce, potřebu dekódovací logiky i další související faktory. Na základě právě popsaného výzkumu se pak dospělo k závěru, že nejlepším a zároveň také kompromisním řešením bude konfigurace šestnácti 32bitových registrů (R0...R15). Můžeme tak zajistit nejlepší možnou kombinaci v otázce výkonnosti, velikosti kódu a také nezbytného rozměru „křemíkového základu“.
R1 až R15 lze přitom využít jako datové nebo adresové registry. R0 slouží ještě jako univerzální registr nebo Stack Pointer (SP). Samotný Stack Pointer pak pracuje buď jako Interrupt Stack Pointer (ISP) nebo User Stack Pointer (USP) a to na základě hodnoty výběrového bitu SP (U), který nalezneme ve stavovém slovu procesoru Processor Status Word (PSW).
V rámci RX a jejich jádra CPU rovněž nalezneme Floating Point Unit (FPU), prvek v této třídě poněkud neobvyklý. Nasazení FPU je prozíravé, protože spíše než vlastní sadu registrů využívá registry základní jednotky CPU. Zabráníme tak přídavné komunikaci, obvykle spojované s implementací běžných FPU, které vystupují spíše jako koprocesor, zatímco v případě našich struktur RX hovoříme o FPU, která je “hluboce usazenou” výpočetní jednotkou v samotném nitru jádra CPU. FPU podporuje akumulaci, multiplikaci, dělení, odčítání a také celočíselné převody.
Pro celočíselná data nabízí CPU RX další výpočetní jednotky, kterými jsou násobička, dělička nebo Barrel Shifter. Vhodně podporují DSP algoritmy, např. pomocí Repeat Multiply Accumulate (RMAC), jak je běžné v případě filtrů a jejich výpočtů.
Mezi další důležité činitele řadíme rychlou reakci na přerušení. Jádro obvodů RX bylo z tohoto důvodu vybaveno naprosto flexibilním systémem přerušení, aby tak mohli vývojáři perfektně vyladit činnost mikrokontroléru, který bude konkrétní aplikaci podporovat nejlepší možnou měrou. K dispozici máme tři různá přerušení:
- Obyčejné přerušení (Normal Interrupt)
- Rychlé přerušení (Fast Interrupt) a také
- Vysokorychlostní přerušení (High Speed Interrupt).
Obyčejné přerušení uchovává příslušné registry na stacku za přispění instrukcí push/pop, takže všechny obecné registry budou volně použitelné v souvislosti s Interrupt Service Routine. V případě rychlého přerušení automaticky ukládáme stavové slovo procesoru a Program Counter do speciálního backup registru (BPSW a BPC), takže může docházet k rychlejší odezvě.
V případě vysokorychlostního přerušení zvyšujeme rychlost ještě více – k vyhrazenému použití zde totiž vyčleňujeme až čtyři obecné registry. Odezva na přerušení pak může trvat jen 5 hodinových cyklů.
Struktura interní sběrnice zajišťuje 5 vnitřních sběrnic, starajících se o to, aby nedostatečná průchodnost zbytečně nedegradovala rychlou práci s daty. Šířka instrukční sběrnice je 64 bitů, všechny zbývající sběrnice jsou pak 32bitové. Struktura dále podporuje jednu vyhrazenou sběrnici, díky které lze využívat DMA (Direct Memory Access), DTC (Data Transfer Control) nebo E-DMA (Ethernet Direct Memory Access).
Obvody RX600 mají ještě k dispozici další modul DMA, označený jako EXDMA, který může v jednom sběrnicovém cyklu přenášet data přímo mezi dvěma vnějšími zdroji. Dobře známým příkladem použití se stává propojení externí SRAM a displeje typu TFT. SRAM zde slouží jako frame buffer, přičemž EXDMA přenáší zde uložená obrazová data do TFT bez jakékoli zátěže interního provozu MCU RX.
Jak již bylo řečeno, šířka instrukční sběrnice činí 64 bitů, takže díky proměnné délce instrukcí, použitých v rámci architektur CISC, můžeme v jediném hodinovém cyklu natáhnout 1 až 8 instrukcí. Hovoříme pak o 5stupňovém pipeline se čtyřmi instrukčními frontami (8 byte). Instrukce se pak nahrávají do front dokud se nenaplní a to bez ohledu na dokončení dekódovací fáze. Běžně používané instrukce jsou krátké a velikost kódu tak zbytečně nemusí narůstat. Spousta instrukcí se navíc provádí jen v jednom hodinovém cyklu, což představuje další zrychlení. CPU má k dispozici 73 základních, 8 floating – point a 9 DSP instrukcí. Nechybí ani 10 adresovacích režimů (registr – registr, registr paměť, bitová orientace).
Memory Protection Unit (MPU)
Moderní aplikace bývají provozovány v drsných podmínkách, kde potřeba bezpečnosti, spolehlivosti a také zajištění vzrůstá se složitostí celého systému. Vývojáři, a občas také i místní legislativa, z těchto důvodů vyžadují hardwarové prvky s podporou a dohledem nad systémovou integritou a její odolností vůči nahodilým změnám softwaru, splašenému kódu, poruchám paměti, lehkým chybám a podobně. A aby toho nebylo málo, v případě rostoucí složitosti softwarového řešení bývá vývoj často rozdělen mezi několik různých týmů nebo dokonce společností. Použijeme – li hardwarové prostředky k oddělení různých softwarových elementů vůči sobě navzájem, můžeme zajistit, že špatně napsaný software od jednoho týmu neohrozí dobře vymyšlený software další skupiny. RX takovou hardwarovou podporu nabízí ve formě Memory Protection Unit (MPU). Pod jednotkou MPU si můžeme představit jakýsi hardwarový firewall mezi privilegovaným kódem operačního systému a kódem aplikačním. V případě softwaru třídy B a C takový rys umožní jednoduchou detekci selhání, flexibilní zacházení s již vzniklou chybou a také nárůst celkové spolehlivosti použitého softwarového řešení. MPU nabízí až osm jednotlivých oblastí i s jejich vlastními přístupovými právy. Nejmenší jednotka přitom bude tvořena 16 Byte. Celý adresový prostor můžeme definovat jako prostředí s jeho vlastními ochrannými atributy. MPU spouští výjimku na základě detekce narušení ochranného atributu. Narušení jsou detekována během přístupu k operandům a vyvolávání instrukcí:
- Narušení ochranných atributů pro platnou oblast
- Narušení atributů přístupem do části oblasti, jiné než té platné
- Narušení atributů pro statickou oblast
Nasazení MPU umožňuje spolehlivé a také nekompromisní oddělení mezi chráněným kódem a související nechráněnou částí. Budeme – li navíc srovnávat se softwarovými snahami o dosažení bezpečného a také spolehlivého programu, zjistíme, že jsme dosáhli menší velikosti kódu. Zcela přitom zaručujeme odezvu v reálném čase.
RX a nízkopříkonové technologie
Použití pokročilých vývojových nástrojů ve spojení s nejnovější technologií 90 nm procesů umožnilo společnosti Renesas optimalizovat návrh CPU RX s ohledem na malou spotřebu, přičemž maximální výkon CPU nesměl nikterak utrpět. Speciální nástroje pomohly analyzovat kritické trasy všech částí CPU včetně jejich časování a následně vybrat rychlé tranzistory pouze tam, kde jejich vlastnosti skutečně oceníme, zatímco zbylé polovodiče v nekritických úsecích zůstaly pomalejší, ale zato s podporou malé vlastní spotřeby. Pokročilá distribuce hodinového taktu zase podpořila uživatele ve snaze dynamicky konfigurovat daný obvod s cílem zajistit, kdykoli to bude nutné, ty nejmenší proudové odběry. Ve spojení s moderní technologií MONOS Flash pak struktury RX nabídnou nejvyšší výkony, přičemž spotřebují jen 0.3 mA/MIPS.
RX však nenabízí jen maximální výkony s nejnižší spotřebou v aktivním režimu. Polovodičové struktury byly rovněž navrženy s cílem minimalizovat odběry v nízkopříkonových režimech. Zapracováním módu Deep Standby můžeme stále udržovat v činnosti některé základní funkce a ještě k tomu spotřebovávat méně než 20 uA.
Embedded Flash a technologie MONOS
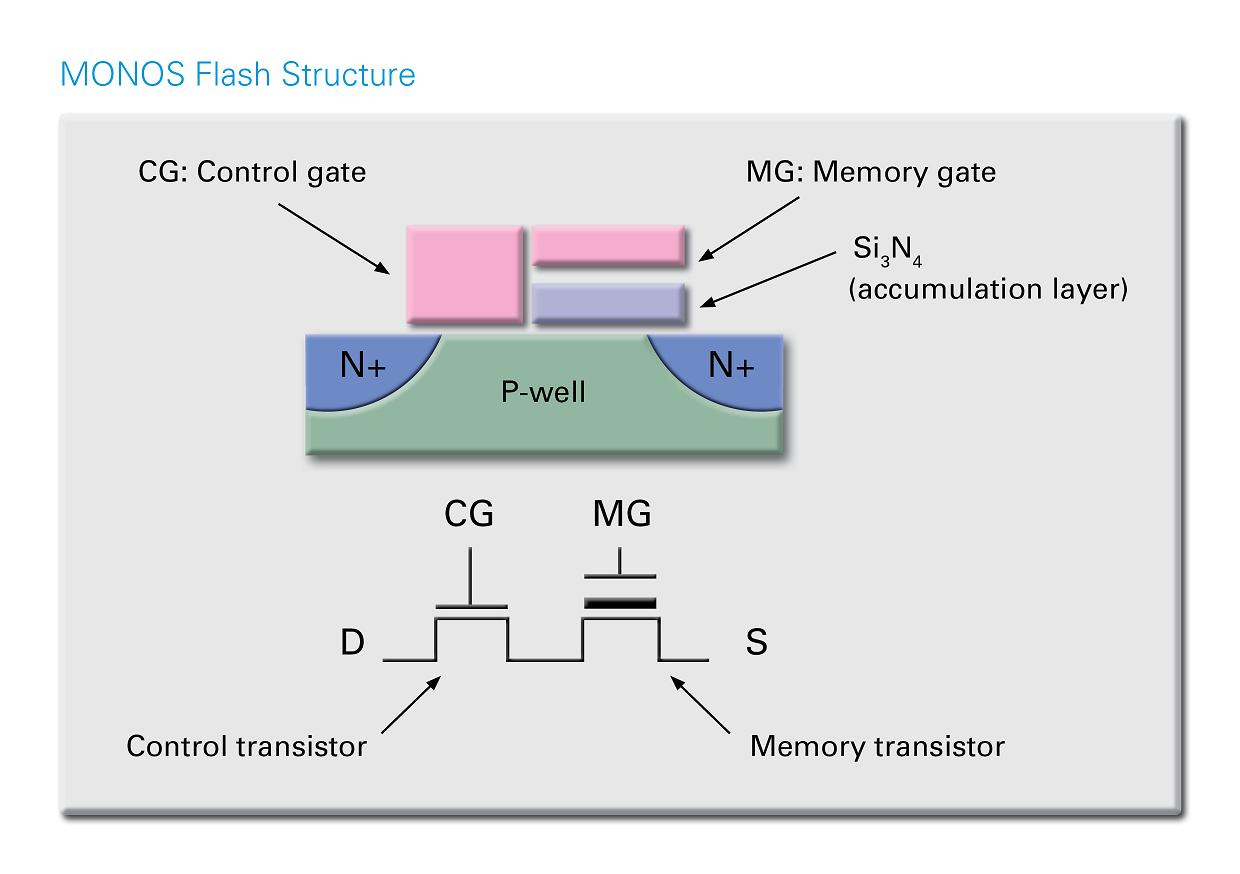
Renesas po desetiletí byl a stále je “průmyslovým tahounem” v oblasti non – volatilních technologií pro embedded paměti. Produkce tento rok překročila hranici 1.5 bilionů kusů a se závadou typu ztracených dat jsme se ještě nesetkali. Řada RX600 využívá technologii MONOS Flash, vykazující bezkonkurenční přístupovou dobu 10 ns pro čtení spolu s vysokou mírou spolehlivosti z titulu nevodivého plovoucího hradla (nitrid). Náboje jsou tudíž “uvězněny” a případná porucha tak ovlivní jen několik z nich na rozdíl od tradičních, vodivých plovoucích hradel kde může porucha způsobit “zmizení” veškerého náboje s nepříjemným následkem v podobě změny stavu příslušného bitu. Nitridové plovoucí hradlo tak vlastně vystupuje jako vestavěná redundance. MONOS Flash MCU společnosti Renesas byly dostatečně prověřeny časem, jsou v nabídce již 10 let a ustály i tak náročné aplikace jako je řízení motorů nebo oblast frekvenčních střídačů v průmyslu. Způsob provedení plovoucího hradla však není jediným speciálním rysem právě zmíněné technologie. Na stránkách výrobce se použité technologii a také veškerým “vychytávkám” věnujeme podrobněji.
RX a periférie
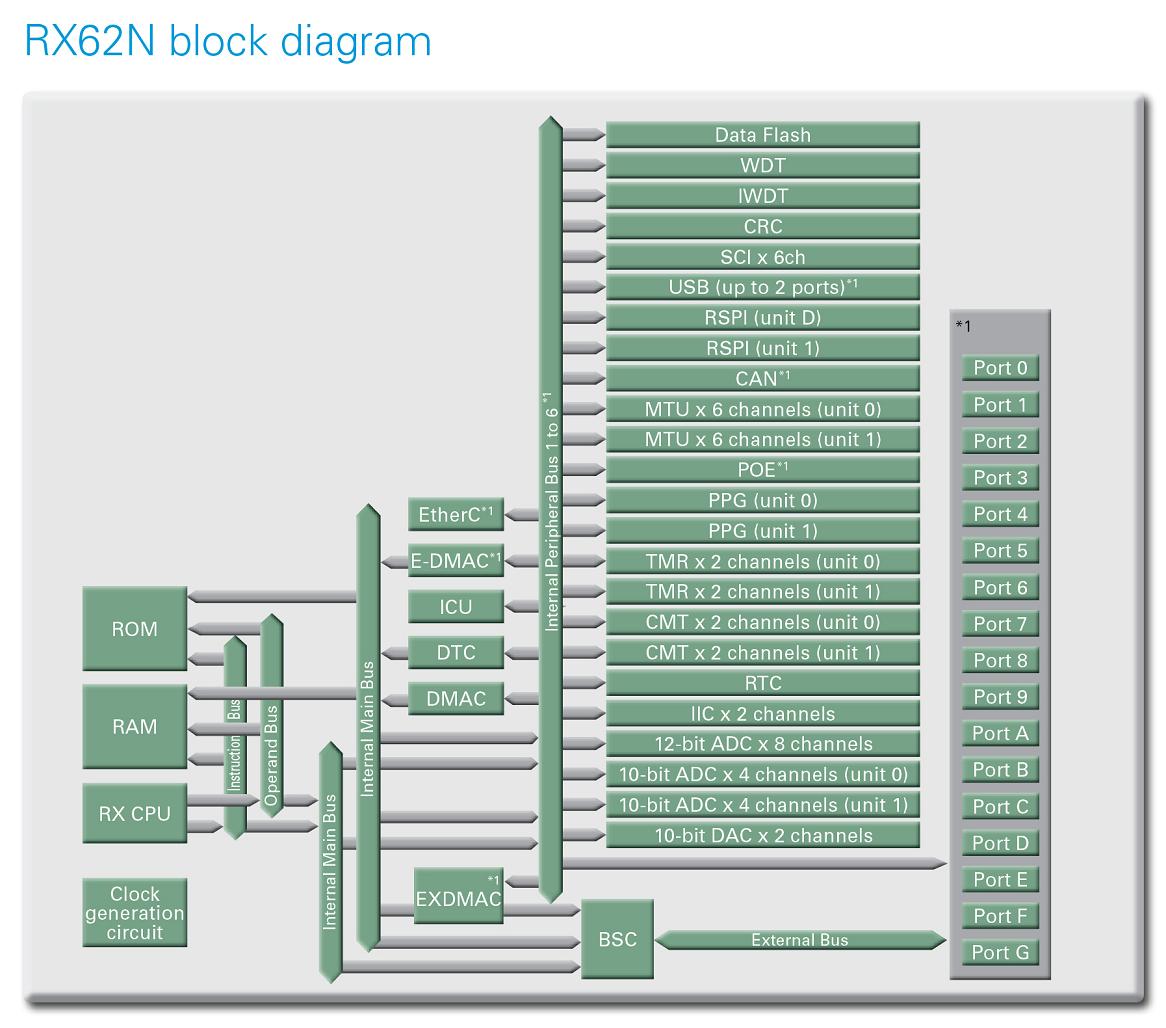
Jedním z prvních obvodů RX se stala struktura RX62N, zastřešující vstup do nové rodiny polovodičů. Jedná se o univerzální přístup s bohatou výbavou, podporující celou řadu projektů a to dokonce i v případech, kdy budeme mít nejprve přemíru obvodů a pro samotnou výrobu vybereme jen určitou podskupinu z nich.
RX62N jsme zobrazili níže. Skládá se z 512 K Flash, 32 K DataFlash, 96 K RAM včetně periférií i s jejich nesčetnými možnostmi (USB host/function/OTG, CAN, Ethernet, mnoho sériových portů různých typů, 10 a 12bitový ADC, DAC, spousta timerů, DMA/DTC/EXDMA, power-on reset, detekce nízkého napětí a mnoho dalšího). Abychom byli také nápomocni v případě aplikací, zaměřených zejména na datovou integritu, zapracovali jsme užitečnou jednotku CRC se kterou lze například prověřit obsah paměti nebo také data sériové komunikace. Vedle zastřešující struktury RX62N bude Renesas také rozvíjet ASSP přístup, zaměřený na řízení motorů se speciálními perifériemi typu sofistikovaných, 12bitových A/D převodníků včetně příslušných timerů, vyhovujících tomuto segmentu. Kromě toho všeho budou nové ASSP zahrnovat speciální periférie, určené pro měření elektrické energie, bílé zboží nebo lékařskou elektroniku.
RX a vývojové nástroje
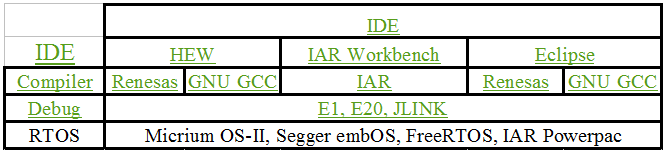
Jak můžeme vidět v následující tabulce, rodinu obvodů RX podporuje řada kompilátorů, debuggerů, IDE a RTOS. Vemte prosím v úvahu, že se nabídka bude nadále rozšiřovat a že připadají v úvahu prakticky všechny kombinace zmíněných alternativ.
Jádro RX zahrnuje specifickou hardwarovou podporu ladění, umožňující přístup do paměti v reálném čase, stejně takové trasování nebo virtuální com porty pro opravdově neintruzivní ladění. On chip trasa je zvýrazněna datovou komprimací v reálném čase, umožňující vzorkování až 2 milionů branch cyklů. Každý bit v rámci 16bitové zprávy přitom reprezentuje podmiňovací instrukci větvení. V případě obsazené větve pak dochází k nastavení bitu (Set), v opačném případě k jeho resetu. Debugger poté přestaví trace buffer a proto se může zdát, že se jedná o mnohem více než zmíněné dva miliony cyklů. Díky virtuálním com portům jádra RX mohou vývojáři upravit svůj kód s jednoduchými příkazy printf a to dokonce i v případě, že již byly upotřebeny všechny sériové porty daného čipu. S takovou vlastností se v dané třídě obvodů jinde nesetkáme.
K této věci vyhrazený DMA kontrolér se zase postará o monitorování dat a C/C++ proměnných v reálném čase stejně jako o nastavení hardwarových breakpointů bez nutnosti zastavení.
Shrnutí a výhled do budoucnosti
![]() Jádra CPU byla v rámci obvodů RX navržena tak, aby běžela až na 200 MHz. Přidáme – li k tomu 1.65 MIPS/MHz, dostaneme široký prostor pro aplikace nového desetiletí a ještě dále. V Renesas se budou i nadále využívat nejnovější výrobní technologie – na rok 2012 se plánuje spuštění 65 nm MONOS Flash, přičemž pro další fáze máme v hledáčku rovněž RX struktury, založené na MRAM. Zkrátka a jednoduše, pod označením Renesas hledejme přední technologie, mocný výrobní potenciál s podporou prodloužené životnosti, podporu vývoje a v neposlední řadě také rychlé tempo vývoje nových produků – prostě vše co vývojáři na začátku žádali po džinovi (duch v orientálních pohádkách...).
Jádra CPU byla v rámci obvodů RX navržena tak, aby běžela až na 200 MHz. Přidáme – li k tomu 1.65 MIPS/MHz, dostaneme široký prostor pro aplikace nového desetiletí a ještě dále. V Renesas se budou i nadále využívat nejnovější výrobní technologie – na rok 2012 se plánuje spuštění 65 nm MONOS Flash, přičemž pro další fáze máme v hledáčku rovněž RX struktury, založené na MRAM. Zkrátka a jednoduše, pod označením Renesas hledejme přední technologie, mocný výrobní potenciál s podporou prodloužené životnosti, podporu vývoje a v neposlední řadě také rychlé tempo vývoje nových produků – prostě vše co vývojáři na začátku žádali po džinovi (duch v orientálních pohádkách...).
Download a odkazy:
- Domovská stránka Renesas: http://www.renesas.eu/
- Distributor pro ČR



